Leveraging Large Language Models to Build Agent Assistant for Youth Mental Health Issue Identification and Recommendation
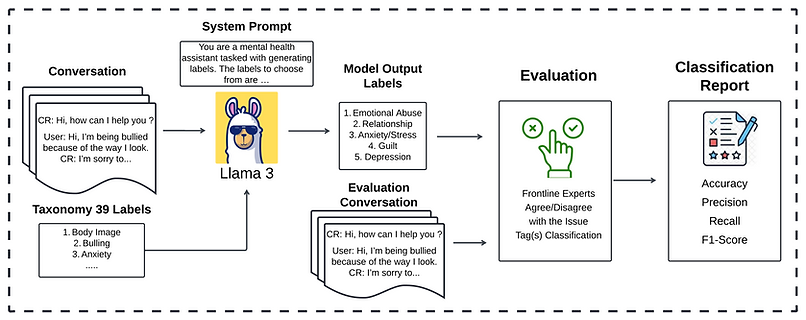
Description:
-
Collaborate with Vector Institute and Kids Help Phone to implement Large Language models to classify and predict mental health issues in young people to reduce the administrative burden on counselors.
-
Using over 700,000 anonymized conversations between KHP's service users and volunteers, we developed an advanced multi-label classification and keyphrase generation system based on LLaMA 3. The model classified mental health issues and generated relevant keyphrases, offering deeper insights into these conversations. This research addresses a critical need for scalable AI-driven solutions in the mental health sector, particularly in youth counseling.
-
The significance of this research lies in its potential to transform the mental health support system. By automating the identification of mental health issues in large-scale, text-based interactions, AI models can significantly enhance the performance of crisis responders. The system provides accurate and efficient classifications of mental health issues, expanding the label set from 19 to 39 categories.
-
The model outperformed the crisis responder’s analysis and was able to find new insights from mental health problems using the chain of thoughts with high-performance evaluation.
-
Skills: Python, Large Language Models, Llama 3, AWS, Text data preprocessing, and system prompt.
-
This work is currently under review and will be published soon.
PhD thesis: Leveraging Artificial Intelligence to Detect and Predict Neuropsychiatric Symptoms (NPS) in Patients with Dementia Within Clinical Settings
%20(1).png)
Description:
-
I received the Ontario Graduate Scholarship for this proposal. In this work, we built a system currently being tested at Ontario Shores Centre for Mental Health Sciences to understand the complicated behaviors of PwD to detect and predict agitation and aggressive using artificial intelligence. This study integrates a Multimodal approach, combining biometric data from the EmbracePlus wristband and video data from cameras installed in the dementia unit. Data collected by devices, along with the results of the data analysis, will be compared against the nurse notes and cameras to confirm the agitation and pre-agitation events.
-
I presented preliminary results from a real-world study at the Ontario Shores Center for Mental Health Sciences. The study outcomes indicate that by using sequential feature selection, we are able to improve detection accuracy while reducing the number of features from an initial set of 198. Further, the Extra Trees classification model output formed other algorithms in accurately classifying agitation events. The study also shows that personalized models yielded superior results.
-
This work is currently under review and will be published soon.
Investigating Multimodal Sensor Features Importance to Detect Agitation in People with Dementia

Description:
-
I collaborated with Dr. Shehroz Khan at University Health network and University of Toronto [11] to investigate using a new set of features with various machine learning models to detect individual patterns of NPS. These features are extracted from sensor data collected by multimodal wearable devices from 17 PwDs admitted to a specialized Dementia Unit in Canada. Several machine learning models are trained using these features, and our findings show that Extra Trees achieves higher performance with the new feature set compared to the state-of-the-art feature set known to date.
-
We found features like the line integral, 5th and 95th percentile, and features from the temperature signal among the top features to classify agitation events. We fed the best set of features we extracted into several machine learning algorithms and Extra Trees yielded the best performance with a median AUC of 0.941, AUC Min of 0.837, and AUC Max of 0.994. These results show good improvements compared to previous state-of-the-art work. We show that exploring more features and other machine learning algorithms can enhance the results by uncovering more information from the raw sensor data, which is crucial to improving classification performance.
Master's Degree Thesis: Human Activity Recognition From Wearable Sensors Using Machine Learning and Feature Selection

Algorithm and Techniques: multilayer perceptron (MLP), naive Bayes (NB), random forest (RF), k-nearest neighbor (k-NN), support vector machine (SVM), and decision tree (DT), and Sequential Feature Selector.
Language: Python
Libraries: Pandas, NumPy, scipy, matplotlib, statsmodels, sklearn, math, csv.
Description:
-
This research addresses the challenge of recognizing human daily activities using surface electromyography (sEMG) and wearable inertial sensors. Effective and efficient recognition in this context has emerged as a cornerstone in robust remote health monitoring systems, among other applications.
-
We propose a novel pipeline to attain state-of-the-art recognition accuracies on a recent-and-standard dataset—the Human Gait Database (HuGaDB). Using wearable gyroscopes, accelerometers, and electromyography sensors placed on the thigh, shin, and foot, we developed an approach that jointly performs sensor fusion and feature selection. Being done jointly, the proposed pipeline empowers the learned model to benefit from the interaction of features.
-
Using statistical and time-based features from heterogeneous signals of the aforementioned sensor types, our approach attains a mean accuracy of 99.8%, which is the highest accuracy on HuGaDB in the literature. This research underlines the potential of incorporating EMG signals especially when fusion and selection are done simultaneously. Meanwhile, it is valid even with simple off-the-shelf feature selection methods such as the Sequential Feature Selection family of algorithms. Moreover, through extensive simulations, we show that the left thigh is a key placement for attaining high accuracies.
Pre-trained Deep Learning Models for Coronavirus (Covid-19) Prediction from Chest X-ray images
Algorithm and Techniques: Pre-trained models VGG16, VGG19, and Dense-Net201 using transfer learning.
Language: Python
Libraries: Python, TensorFlow, Keras, Sklearn, Open CV, matplotlib, Pandas, and NumPy.
Description:
-
I proposed several image processing techniques to augment COVID-19 X-ray images to generate a large and diverse dataset to boost the performance of deep learning algorithms in detecting the virus from chest X-rays.
-
I also proposed innovative and robust deep learning models, based on DenseNet201, VGG16, and VGG19, to detect COVID-19 from a large set of chest X-ray images. A performance evaluation shows that the proposed models outperform all existing techniques to date. Our models achieved 99.62% on the binary classification and 95.48% on the multi-class classification.
.png)
IBM Data science project: Opening a middle eastern restaurant in Toronto
Algorithm and Techniques: k-means clustering.
Language: Python
Libraries: Pandas, NumPy, matplotlib, sklearn, BeautifulSoup, seaborn, JSON,.
Description:
-
This study aimed to explore different neighborhoods in Toronto based on criteria collected from different datasets.
-
The first criteria are from the neighborhood profile dataset which includes Total Population, Persons living alone, Ethnic origin (Middle Eastern), Language (Arabic), Target Age (youth and working age), and Target income (40,000$ +).
-
The second criterion is the crime rate in each neighborhood which is calculated from the Neighbourhood Crime Rates dataset and includes different types of crime.
-
Finally, FourSquare API is used to find the top 10 common venues from each neighborhood to ensure that the selected neighborhood won’t have any other middle eastern restaurant.

Real-Time Data Streaming with Apache Kafka and AI for Health Risk prediction of ECG signals
Algorithm and Techniques: Random Forest (RF), K-Nearest Neighbors (KNN), Support Vector Machine (SVM), ExtraTreesClassifier, and artificial neural network(ANN).
Language: Python
Tools: Raspberry Pi 3 B+, Apache Kafka, MQTT, Twilio for notifications, and Tkinter for data visualization.
Libraries: Pandas, NumPy, matplotlib, sklearn, tKinter, Twilio, Tensorflow, and Keras.
Description:
-
We perform an initial detection phase where ECG data is collected with lightweight deep learning analysis.
-
We Implement and deploy a binary classification system for ECG signals in constrained environments as near as possible to data production to decrease the time to act and alert caregivers of their patients' potential life-threatening situations.
-
Developing an effective and scalable real-time stream engine for ECG signals from a body worn ECG patch to the backend system.
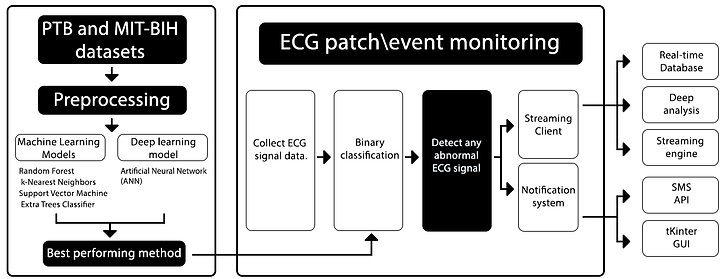
Tableau Public projects
Description:




Movie Rating Prediction from IMDB Dataset
Algorithm and Techniques: GradientBoosting, Random Forest, KNN, and Extratrees classifiers to classify the dataset.
Language: Python
Libraries: Pandas, NumPy, seaborn, matplotlib, sklearn, BeautifulSoup, seaborn, JSON.
Description:
-
We used a dataset that only included movies after the year 2000. We narrowed down the movies with at least 10,000 raters and a budget of at least 10,000 USD. This was done in order to eliminate the newer movies that did not have enough ratings submitted to be fairly judged and would reduce the accuracy of the data.
-
There were also an amount of very low-budget movies which were traditional movies in a sense so we set the budgetary limit to eliminate those movies from causing errors in our predictions as well.
-
We classified the data by converting the IMDb ratings into three categories: category 0, category 1, and category 2. The target labels were 0-4 for category 0, 4-7 for category 1, and 7-10 for category 2.
-
There were two steps for our data classification: Data testing and Data training. We used 75% of the data as training data and the remaining 25% was used for training. We utilized multiple data classifiers to perform these data classifications in order to maximize prediction accuracy by choosing the classifier that yields the most accurate results. We compare different algorithms.
-
From the four different classifiers we utilized, as expected, we obtained varying levels of accuracy with each one. The exact accuracy percentages for the classifiers are as follows: Gradient Boosting 75.30%, Random forest 82.53%, KNN 65.06%, and Extratrees 77.71%. As we noticed, the most accurate of the classifiers for our classification was the Random Forest classifier with approximately 82.5%.
Character name extraction from movies screenplays NLTK
Algorithm and Techniques: Natural Language Toolkit
Language: Python
Libraries: NLTK, Pandas, NumPy, seaborn, matplotlib, sklearn, BeautifulSoup, seaborn, JSON,.
Description:
-
In this project, we develop an algorithm to read the screenplays and automatically extract the character names from the screenplay.
-
We propose a solution to create training data and we design two algorithms and compare them.
-
We propose an evaluation metric and evaluate the result of your algorithm with the proposed metric.

Screenplay genre Classification
Algorithm and Techniques: Extratrees classifier, Random forest classifier, and MLP classifier
Language: Python
Libraries: Pandas, NumPy, seaborn, matplotlib, sklearn, BeautifulSoup, pickles, URL, seaborn, JSON.
Description:
-
In this work, we develop an algorithm to read the screenplays and automatically predict the genre of the movie.
-
We design the algorithm and propose a solution to create training data
-
We propose an evaluation metric and evaluate the result of your algorithm with the proposed metric.

MedTourEasy internship project: Analyze Your Runkeeper Fitness Data
Language: Python
Libraries: Pandas, NumPy, matplotlib.
Description:
-
The first step is to export the data from Runkeeper. Then import the data and start exploring to find potential problems. After that, create data cleaning strategies to fix the issues. Finally, analyze and visualize the clean time-series data.
-
This dataset is exported from seven years worth of training data, from 2012 through 2018. The data is a CSV file where each row is a single training activity.

IMDB movies web scraping to collect metadata of top 250 movies
Libraries: Pandas, NumPy, matplotlib, BeautifulSoup, seaborn, urllib.
Description:
-
This code writes and implements an algorithm to automatically collect as much metadata as possible of the 250 titles from IMDB and store them in a CSV file.
-
It also implements an automated script to search, find, download the screenplay of each title and store each screenplay as (Semi) structured data.
DataCamp project: Predicting Credit Card Approvals
Algorithm and Techniques: logistic regression, Grid searching
Language: Python
Libraries: Pandas, NumPy, sklearn.
Description:
-
We'll use the Credit Card Approval dataset from the UCI Machine Learning Repository.
-
First, we will start off by loading and viewing the dataset.
-
We will see that the dataset has a mixture of numerical and non-numerical features, contains values from different ranges, and contains a number of missing entries.
-
We will have to preprocess the dataset to ensure the chosen machine learning model can make good predictions.
-
After our data is in good shape, we will analyze exploratory data to build our intuitions.
-
Finally, we will build a machine learning model that can predict if an individual's application for a credit card will be accepted.

3D-RadViz: Three Dimensional Radial Visualization for Large-Scale Data Visualization ( Group project )
Language: Python
Libraries: Plotly, matplotlib, Pandas, NumPy, sklearn.
Description:
-
This work was a group course project during my PhD and our work was selected from top three projects to publish a paper about it. The proposed technique extends the capabilities of the classical two dimensional radial visualization (RadViz) in order to reduce overlapping data points. For evaluation purposes, we applied 3D-RadViz alongside with t-SNE and a recently published 3-dimensional radial visualization technique to the same real-world datasets from the UCI machine learning repository. The contribution of the work is an interactive, deterministic, and high-performance library, implemented in Python, that can be utilized to realize better high dimensional data visualization using the proposed 3D-RadViz technique.
Undergraduate Project: PortaCare: IoT-Based Portable-Intensive-Care-Unit ( Group project )
Language: C++ and Arduino
Description:
-
The project aims to design a prototype for a low-cost portable intensive care unit with the simplest, yet efficient, techniques that can be used at home.
-
The functions of the prototype and the brief description of it:
1- Heart rate & ECG: Measuring patient’s heart rate, graphing it, and setting an alarm if any sudden change happens.
2- Breathing rate: Measuring patients breathing rate to detect any irregularities and to maintain respiration efficiency.
3- Oxygen level in blood: an estimate of the amount of oxygen in the blood.
4- Glucose level in blood: measures the amount of glucose in your blood.
5- Measure the body temperature.
-
PortaCare is also integrated with a medication box or a pill reminder as a part of the prototype, the Pill Reminder is an internet of things (IoT) enabled device to prompt a person when it is time to take their pills.
-
Won national funding from (ITIDA) Information Technology Industry Development Agency) and National Telecommunications Regulatory Authority (NTRA) of Egypt for one of the best functional prototypes
